
This course offers a comprehensive introduction to statistical and machine learning methods. Topics covered include:
- Foundations: review of probability and statistics, nonlinear optimization (gradient descent, Newton’s method).
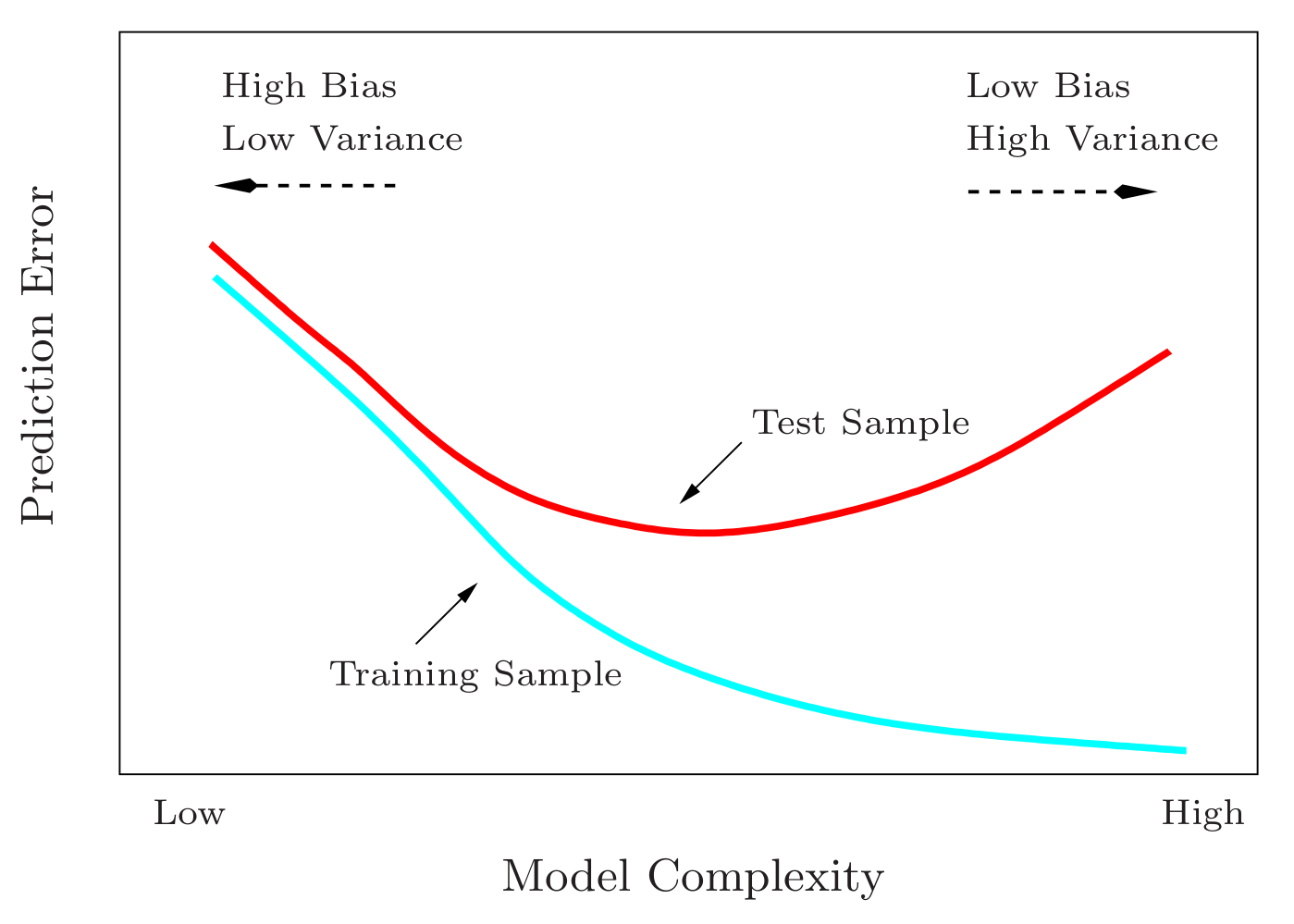
- Supervised learning (regression and classification): training and test errors, examples of parametric and non-parametric models (e.g., polynomial regression, k-nearest neighbors), model evaluation and selection, bias-variance trade-off, underfitting and overfitting.
- Resampling methods: cross-validation.
- Linear models: linear regression and interpretation, subset selection, regularization techniques (ridge and LASSO).
- Classification models: logistic regression, naive Bayes, linear and quadratic discriminant analysis.
- Nonlinear models: decision trees for regression and classification (based on entropy and Gini index).
- Ensemble methods: bagging, random forests, boosting.
- Unsupervised learning: dimensionality reduction, principal component analysis.
Exercise sessions and the course project rely on standard scientific computing libraries in Python (NumPy, pandas, scikit-learn).
- Titulaire: Souhaib BEN TAIEB
- Co-titulaire: Pierre VANDENHOVE
- Assistant: Yorick ESTIEVENART